Overview
Problem
Neural Machine Translation (NMT)
Consider machine translation, where we want to translate French into English. In this case, we have a large dataset of text pairs: French sentences and the corresponding English sentences.
French:
Mon Dieu, nous avons trop d’Adityas dans le club.
English:
God, we have too many Adityas in the club.
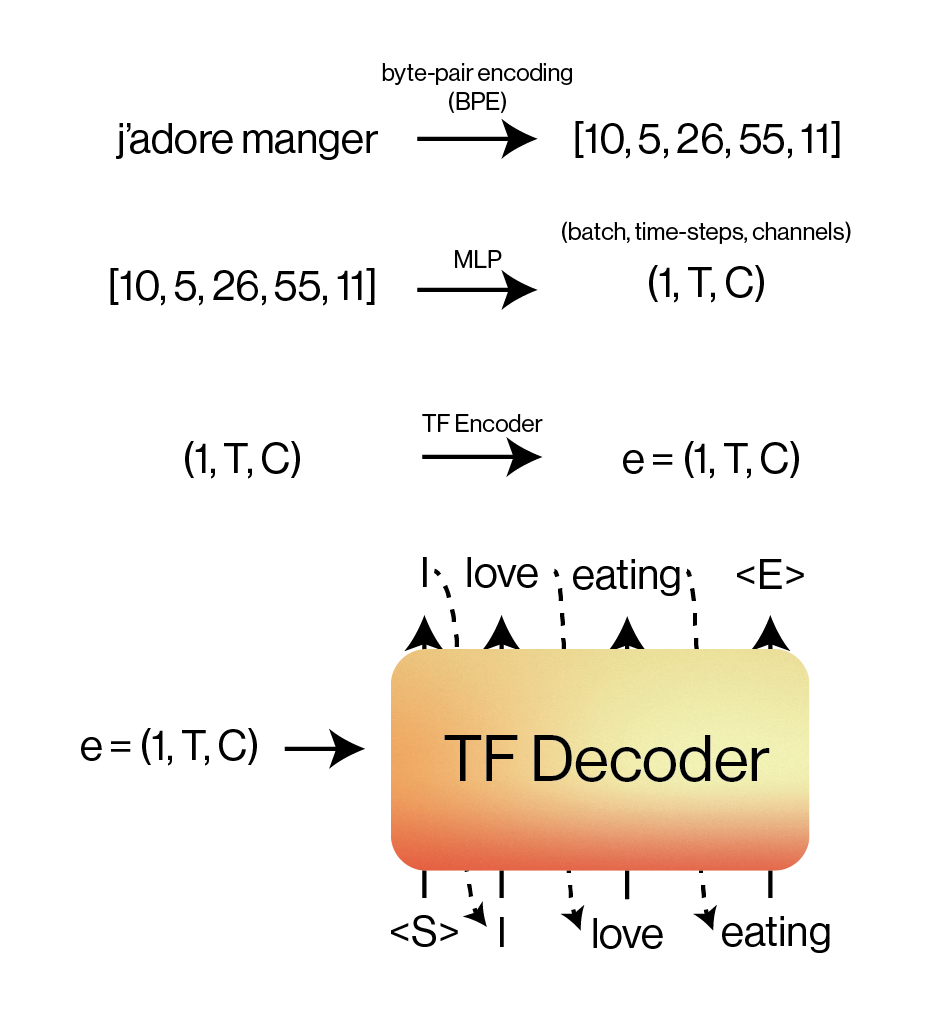
We’ll use a classic encoder-decoder architecture to tackle this problem.
- Convert natural text (raw French and English) into tokens that our Transformer model can understand.
- Encode each French token into an embedding (e.g. using an MLP).
- Encode the full token embedding again using the Transformer encoder.
- Use the Transformer decoder and the encoder embedding to autoregressively generate the English translation.
Language Modeling (LM)
We’ll also use our Transformer to build GPT (Generative Pretrained Transformer)! The original GPT-2 and GPT-3 are actually very similar to what we’ll be making, which is a language model.
A language model tries to mimic and understand how humans produce natural language (modeling language). In general, modeling typically means a probability model, so we’ll be working on the next token prediction task.
The cow jumped over the ______
Here, we have all this rich context preceding our blank line, which is how we know that “moon” should be the last word here. Internally, we have a sense of what words are most probable given a certain context (whether that be forward or backward).
Tasks
We’ll build one model with all the pieces for both the French \(\to\) English translation task and the language modeling task. Here are the steps we will take:
- Tokenization (character-level and byte-pair encoding)
- Transformer Encoder
- Transformer Decoder
- Training scripts for our NMT and LM tasks (we’ll train NMT for French to English and an LM on movie screenplays)
- Train our models!
Setup
Beware! This homework doesn’t have much scaffolding in code. We’ll walk through each part of the architecture conceptually in depth, but we’ll leave it up to you on how you will implement this in code.
Scaffolding
To get started with the scaffolding, you should:
- Fork the repository (click the “Fork” button at the top right of the GitHub page).
-
Clone your forked repository in
honeydew.ssh honeydew git clone git@github.com:[your-username]/sp26-nmep-hw4.git cd sp26-nmep-hw4You can either choose to work in an editor like VS Code that supports SSH or a terminal-based editor like Vim or Neovim.
-
Install
uv(uvis a modern, faster Python environment manager likeconda)curl -LsSf https://astral.sh/uv/install.sh | sh uv sync # this will add a virtual environment and sync all the dependencies source .venv/bin/activate # this will activate the venv we just created -
You’re going to be working in the
seq2seqdirectory (which is built like a Python library). To work with our Python module while editing it, we’ll pip install it.uv pip install -e . # -e means editable, . means in the current directory: the `seq2seq` module defined in `pyproject.toml` -
Next, let’s make sure we have all the data we need. We’ll use the EuroParl dataset for paired French-English sentences.
# make sure you're in the sp26-nmep-hw4/ directory curl -L https://www.statmt.org/europarl/v7/fr-en.tgz --output data/nmt/fr-en.tgz # nmt stands for neural machine translation mkdir data/nmt/europarl tar -xvf data/nmt/fr-en.tgz -C data/nmt/europarl/ ls data/nmt/europarl/You should see
europarl-v7.fr-en.enandeuroparl-v7.fr-en.frin thelsresults. You can use thehead -n 5 [filename]command to view the first few lines of each file. You’ll see that the lines correspond to paired sentences.For the LM task, we’ve given you the movie screenplays in the
data/lm/folder:ls data/lm/You’ll see many
.txtfiles. Each contains a screenplay from a famous movie from IMSDB. Since there isn’t too much data here, our trained LM won’t be very coherent, but will eventually output something looking vaguely similar to these screenplays.
Fetching updates from the source GitHub repository
We might run into some bugs during the homework! When we push changes to the original homework, you need a way to merge these changes into your forked repository. Here’s how you should set this up:
git remote add upstream https://github.com/mlberkeley/sp26-nmep-hw4.git
git fetch upstream
git merge upstream/main
Every time you need to merge changes from the original repo, you should run the last two commands again!
Structure
You’re set up! Here’s how the project is structured:
├── data
│ ├── lm
│ │ ├── *.txt
│ │ ├── README.md
│ └── nmt
│ └── europarl
├── pyproject.toml
├── README.md
├── requirements.txt
├── ruff.toml
├── scripts # here, we use our implementation to train or test or models.
│ ├── decode_lm.py
│ ├── decode_nmt.py
│ ├── train_lm.py
│ └── train_nmt.py
├── seq2seq
│ ├── __init__.py
│ ├── data # how we import our data into PyTorch Datasets of Tensors.
│ │ ├── __init__.py
│ │ ├── fr_en.py
│ │ └── screenplay.py
│ ├── tokenizer # our character-level and byte-pair encoding tokenizers.
│ │ ├── __init__.py
│ │ ├── bpe_tokenizer.py
│ │ ├── character_tokenizer.py
│ │ └── tokenizer.py
│ └── transformer # our core architecture implementation
│ ├── __init__.py
│ ├── attention.py
│ ├── decoder.py
│ ├── encoder.py
│ └── transformer.py
├── tests # simple shape-based tests
│ ├── test_tokenizer
│ │ ├── __init__.py
│ │ └── test_character_tokenizer.py
│ └── test_transformer
│ ├── __init__.py
│ ├── test_attention.py
│ ├── test_decoder.py
│ ├── test_encoder.py
│ └── test_transformer.py
└── uv.lock
Testing
We provide you with a few simple test for sanity-checking your implementation. This does NOT guarantee that your Transformer implementation is correct, but can provide some information about whether your shapes are at least lining up. Run all tests with:
cd sp26-nmep-hw4 # make sure your uv venv is activated
python -m unittest discover tests
or run a specific test file with
python -m unittest tests/[folder]/[test_file].py
Tokenization
Let’s start working! Our first step will be to build a tokenizer. Remember that we’re working with natural language, which is largely text-based inputs. Similar to how we convert our images to a number-based representation for our CV models, we will convert our text-based inputs to number-based representations as well: tokens.
There are many different tokenization schemes. In this homework, we’ll explore two: character-based tokenization and byte-pair encoding (BPE).
Character Tokenization
At its core, tokenization is a process that takes a string of text:
Dasari? Is that like the water brand?
and converts it into a list of integers that we call tokens:
[15, 42, 11, 254, 2, 32, 68, 99, 11]
How do we map our input text to integers? One option is to assign a number to each character:
\[a \to 0\\ b \to 1\\ c \to 2\\ d \to 3\\ \dots\]Then, to tokenize our input, we simply iterate over the string character by character, and output the corresponding token index every time.
\[D \to 7\\ a \to 0\\ s \to 30\\ \dots\]Dasari? Is that like the water brand?
[7, 0, 30, 0, 29, 16, 56, 94, 16, 30, 94, 31, 15, 0, 31, 94, 21, 16, 20, 8, 94, 31, 15, 8, 94, 37, 0, 31, 8, 29, 94, 4, 29, 0, 23, 7, 56]
Time to implement this ourselves! In seq2seq/tokenizer/character_tokenizer.py, you’ll see a CharacterTokenizer class. Your first task is to implement this tokenizer. Your subtasks are:
- Fill the
self.vocabdictionary with our mapping of \(\text{char} \to \text{index}\) (so the keys ofself.vocabwill be all the characters fromself.characters, and the values will be indices starting from \(0\)). - Implement the
encodefunction, which will take a string text and output aTensorcontaining a list of token indices. - Implement the
decodefunction, which will take aTensorcontaining a list of token indices and return the original string.
After implementing your tokenizer, test with:
python -m unittest tests/test_tokenizer/test_character_tokenizer.py
Byte-Pair Encoding (BPE)
While character-based tokenization is a valid way of encoding your text, it has limitations. In particular, each character doesn’t have any specific meaning inherently attached to it. If we see words like “old”, “older”, and oldest”, it would help to repeat a single token for “old” that allows models to see that these words are related. Additionally, character-based tokenization leads to very, very long sequences, which will eventually require more compute to process.
But if we went to the other extreme and tried to give every English word a separate token, our vocab size would be huge (!) and we still run into the “old”/”older” problem. Byte-pair encoding tokenizes subwords to strike a balance between the two, where “old” and “older” might share a subword token for “old”, with another token for “er”.
We don’t require you to implement BPE, but here’s how it works conceptually: we will iteratively replace the most commonly occuring sequence with a new token.
- You have a large corpus of data you would like to build your BPE with.
-
You start with one token for each unique byte in our data. Assume we start with 100 tokens.
Dasari? Is that like the water brand? [7, 0, 30, 0, 29, 16, 56, 94, 16, 30, 94, 31, 15, 0, 31, 94, 21, 16, 20, 8, 94, 31, 15, 8, 94, 37, 0, 31, 8, 29, 94, 4, 29, 0, 23, 7, 56] - Now, we sweep through the data for all pairs of tokens and note down which pair occurs most frequently. In this case,
[0, 31]corresponding toatoccurs most frequently, so it’ll become the 101th token \(a t \to 101\). - We retokenize our original data with our new vocab, and repeat the process until we reach a desired vocab size or until there are no pairs of tokens that occur more than once.
- At the end, we have a bigger vocab than just the characters:
Takeaway
Tokenization enables us to encode our textual inputs into a number-based representation. Important things to note:
- When we want to batch our sequences for training, we need to make sure all of the sequences are the same length. If the maximum-length sequence in our batch has length \(L\), then we will pad our remaining sequences with a special pad token
[PAD], which has some token index like50267. This is handled for you in the givenDatasets. - To denote when our sequences start and end, we’ll add additional special tokens at the start and end for
Start Of SequenceandEnd of Sequence:[SOS]and[EOS]respectively (also included for you).
With batching, our sequence shape has now been converted as:
\[\text{input text} \to (B, T)\]where \(B\) denotes batch size and \(T\) denotes “time” or “# of tokens”. You should interpret this as: we have \(B\) sequences of length \(T\).
Embedding
From our tokenization, we have a tensor representation for any arbitrary French or English input. Now here comes the fun part - we want to create an embedding for our text. As a reminder, an embedding is some sort of tensor that contains all the essential information about our text.
Generally, this will be in a shape like \((B, T, C)\), containing the batch size (\(B\)), the number of time-steps (\(T\)), and the number of channels (\(C\)). What does this mean? Well, let’s break it down:
Batch size and time-steps we know from the previous step. Number of channels (\(C\)) gives us the length of each embedding. We can choose this to be 256, 512, or really any number - powers of two are common ones for efficient computation.
To be very clear, this means that for every token, we have a \(C\)-length vector that represents it. At the start of our model, we don’t have any contextual information. So compute an embedding, we just use a linear transformation!
Let’s take a look at an example to make this explicitly clear:
Word to embed: “hello”
- Batch size: 1 (we only have one input text to embed)
- Number of time-steps: 5 (this is the length of our tokenized word, which has 5 characters)
- Number of channels: 3 (this is the length of each embedding vector, chosen by us!)
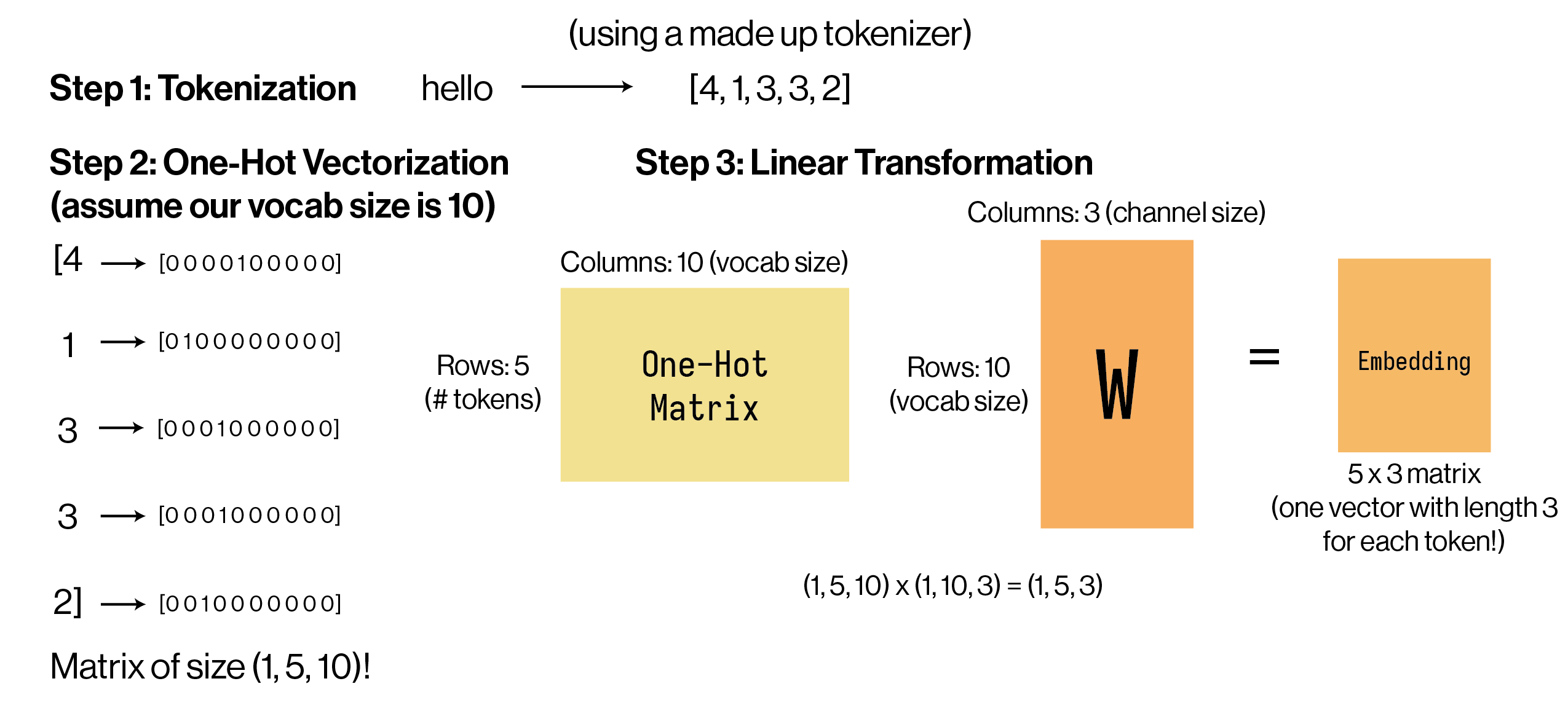
nn.Embedding Simplification
If we look closely at the matrix multiplication, we can notice that for each token, the “multiplication” is just choosing the row in W corresponding to that token!
So, this “linear transformation” is just a lookup table, where we have \(V\) vectors (V being the vocab size), and we look up the vector for each token and pile them together in a \(T \times C\) matrix. This is so common that PyTorch provides us with a nn.Embedding object that creates the differentiable lookup table for us!
At the start of our model, all of these \(V\) vectors contain completely random numbers, and through gradient descent come to represent important information about our tokens.
As a summary, using an Embedding layer, we’ve converted our tokens into token embedding vectors containing token information. We are ready to build our Transformer now!
Shape progress:
\[\text{Tokenize: }\text{input text} \to (B, T)\\ \text{Token Embeddings: } (B, T) \to (B, T, C)\]Transformer
Remember that our translation task has two steps:
- Encode all the information from our French input.
- Use this encoded information to autoregressively generate an English translation.
So, let’s first focus on encoding the French input. At this point, we’ve tokenized the French, then created an embedding for it. We consider our input to the Transformer Encoder to be \((B, T, C)\) and the Transformer Encoder will spit out an output of the same shape \((B, T, C)\)! While going through the Transformer Encoder, each embedding has gathered contextual information from surrounding tokens (by attending to them). Let’s take a look at how this attention process works and implement it.
Attention
The goal of attention is to learn contextual information about this token based on all other tokens. Recall what our embeddings look like:

Also recall what our goal is: for each embedding, we want to search up related embeddings and extract the most important information from them.
Our YouTube analogy is apt! If I want to watch a Mario Kart video on YouTube, I’ll use a query “Mario Kart gameplay”, which will check how similar my query is to a bunch of YouTube titles, which we call keys, and each title has a video value associated with it.
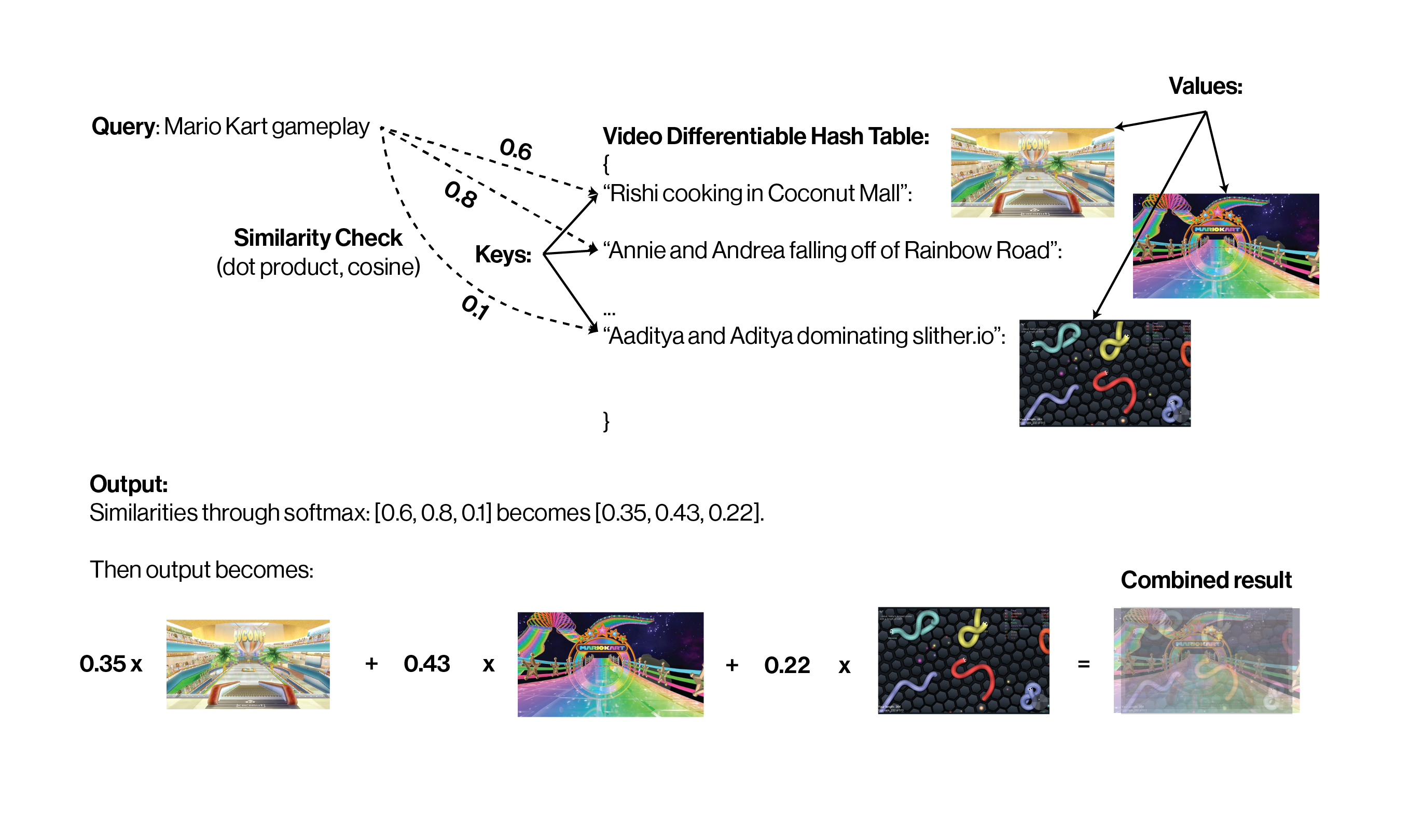
How do we replicate this hash table idea with our embeddings? Well, we use our handy linear transformation tool and just learn (in the machine learning sense) how to make queries, keys, and values!

If we do this for every embedding (see below), we’ll again end up with 5 “out” embeddings, each of which is a weighted sum of our values. If you understand this, you know exactly how the entirety of attention works. Now, just like how we use many kernels in a CNN, we’ll apply this process on these embeddings many times (this is where the “multi-head” term comes from).
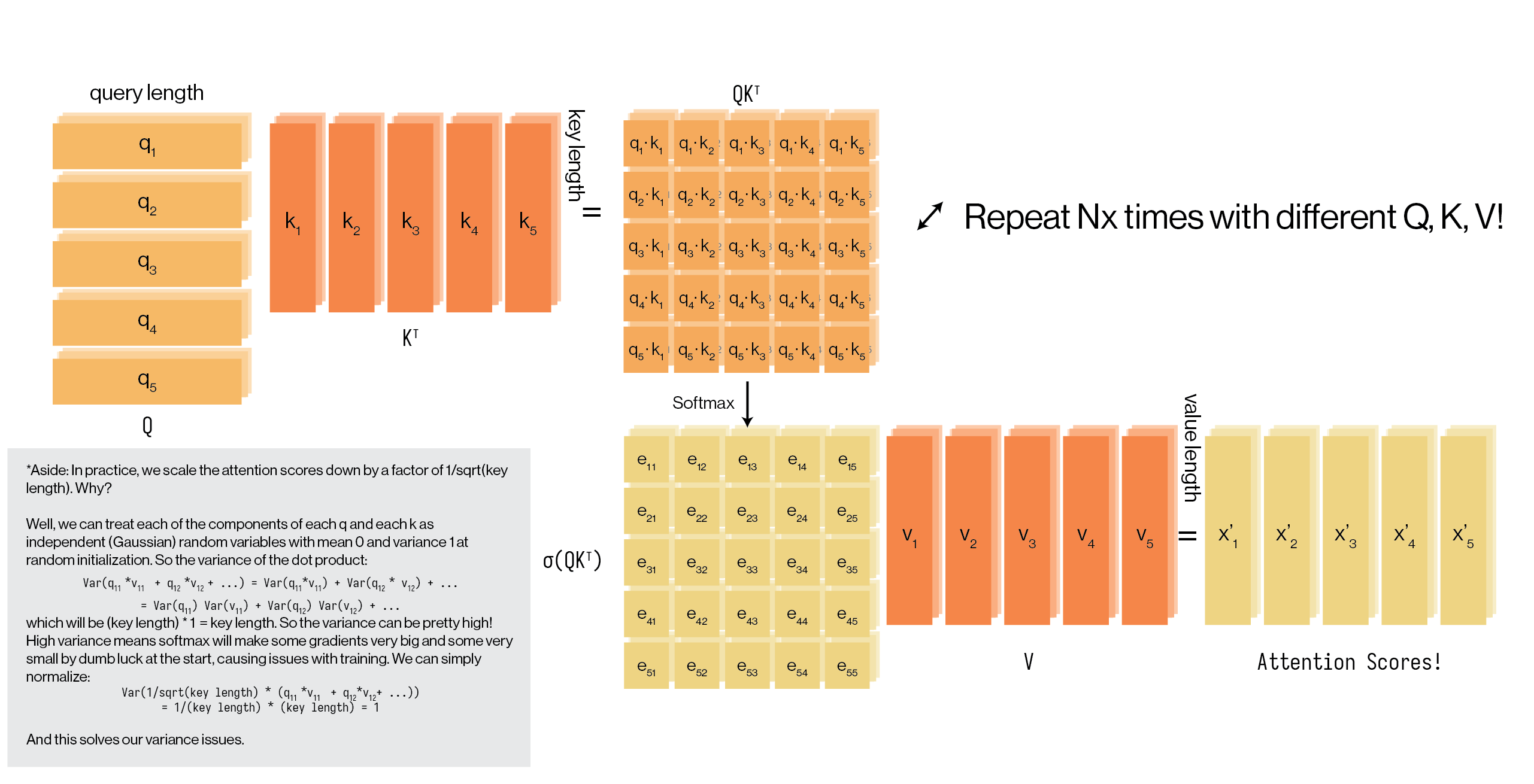
And this is where we get our full scaled dot-product attention equation from the paper:
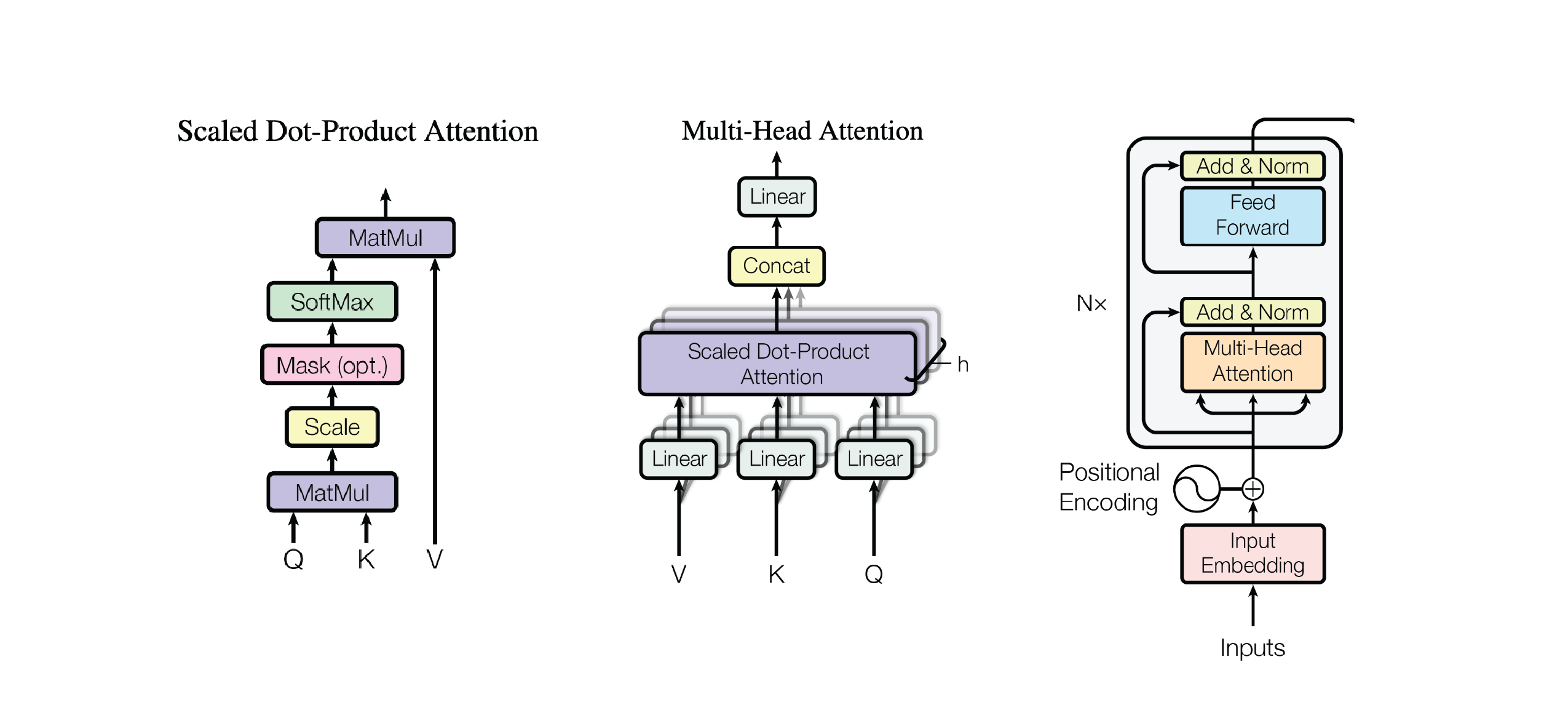
\[\text{attention} = \sigma\left(\frac{QK^{\top}}{\sqrt{\text{qk}\_\text{length}}}\right) \cdot V\]After this diagram, we’ve covered scaled dot-product attention and multi-head attention blocks as described in the Attention Is All You Need paper. You’re ready to implement them yourselves!
Task: Implement the full Transformer Encoder. Subtasks:
- Implement all parts of
MultiHeadAttentioninseq2seq/transformer/attention.py. This includes:__init__,split_heads,combine_heads,scaled_dot_product_attention,forward. Follow the paper closely and use the diagrams for guidance. An implementation of positional encoding is provided for you. - Implement the
FeedForwardNNinseq2seq/transformer/attention.py. All this entails is adding twoLinearlayers that transform your embeddings of size \((B, T, C)\) to some intermediate shape \((B, T, \text{hidden}\_\text{dim})\) with aReLUoperation, then transforming them back to \((B, T, C)\). - Implement the
Encoderinseq2seq/transformer/encoder.py. You’ll need the modules fromattention.py. In particular, implementEncoderLayerand thenEncoder.
After this step, run:
python -m unittest tests/test_transformer/test_encoder.py
You should be passing all these tests (these are purely sanity checks, not correctness checks, which will come during training).
Shape progress:
\[\text{Tokenize: }\text{input French text} \to (B, T_\text{enc})\\ \text{Token Embeddings: } (B, T_\text{enc}) \to (B, T_\text{enc}, C)\\ \text{Encoder: } (B, T_\text{enc}, C) \to (B, T_\text{enc}, C)\]For your reference, here are the Encoder and Attention figures from the original Attention Is All You Need paper:
Decoder
Great! We’ve successfully encoded all the information from our French input into a set of contextual embeddings \((B, T_{\text{enc}}, C)\)
Now, we need to use this encoded information to autoregressively generate an English translation. This is the job of the Decoder.
The Decoder is also a stack of layers, just like the Encoder. However, it’s a bit more complex because it has to manage two different inputs:
-
The Encoder’s output embedding: This is the fully contextualized French sentence (our \((B, T_{\text{enc}}, C)\) tensor). This is where the Decoder gets its information about what to translate.
-
The target sequence: This is the English translation generated so far. For example, if we’re translating “Je suis un” to “I am a”, and we want to predict the next word (“student”), we feed “I am a” \((B, T_{\text{dec}}, C)\) into the decoder as the “target sequence”.
The Decoder’s job is to take these two inputs and produce an output \((B, T_{\text{dec}}, C)\) that represents the best prediction for the next token at each position.
Attention Modifications for Decoding
In the decoder, we have to make some modifications to our attention mechanism: masked-attention and cross-attention.
-
Masked Multi-Head Attention (Self-Attention): This first attention block operates on the target (English) embeddings. It’s almost identical to the Encoder’s self-attention, with one crucial difference: we must prevent the decoder from “cheating” by looking at future tokens.
When we’re at position \(i\) (e.g., trying to predict the word after “am”), we should only have access to tokens at positions \(\le i\) (“I”, “am”). We can’t look at position \(i+1\) (“a”), because we’re trying to predict it!
We accomplish this by applying a look-ahead mask to the attention scores (the \(Q K^\top\) matrix) before the softmax. This mask sets all values corresponding to future positions to \(-\infty\). Remember what the softmax function looks like! If we want attention scores for future tokens to be zero after the softmax, we must set their output after the \(Q K^\top\) matrix to be \(-\infty\).
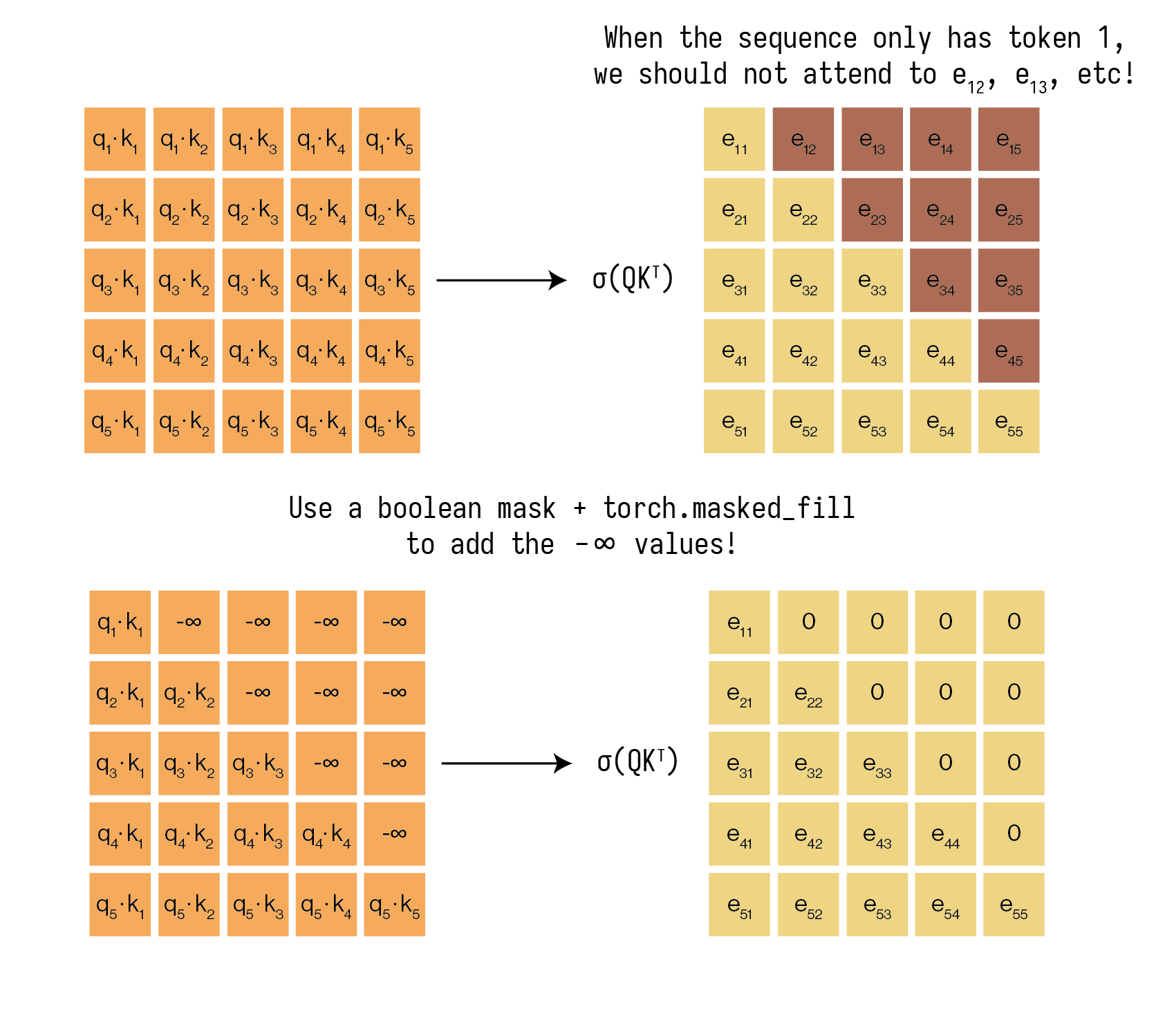
One other place where we need to use this masking is to mask out our pad tokens. Remember that we add our pad tokens when batching multiple sequences together of varying length. If we allow the encoder and the decoder to attend to pad tokens, these tokens will end up dominating our training and lead to divergent models.
The functions to create boolean causal and pad masks for the encoder and decoder are provided in
seq2seq/transformer/transformer.pyasmake_pad_maskandmake_causal_mask. -
Cross-Attention (Encoder-Decoder Attention): Remember that self-attention allows us to attend to tokens within our own sequence. For the Decoder, we also want to look at the French input by attending to the French embedding from the Encoder..
Recall our YouTube analogy. Now, the Query (\(Q\)) comes from the output of our Decoder’s masked self-attention (from step 1). This \(Q\) represents: “I am an English token, this is my context so far. What information do I need from the French sentence to make my next prediction?”
The Keys (\(K\)) and Values (\(V\)) come from the Encoder’s output (the contextualized French embeddings). Remember that keys inform us about which values are relevant: keys and values are tied together and must originate from the same source.
The Decoder’s query (“I am a…”) searches against all the French keys. It might find that its query is most similar to the key for the “suis” token embedding while also attending to the other tokens, and it will then take a weighted sum of the French values to produce its output. This is how it learns the alignment between the two languages.
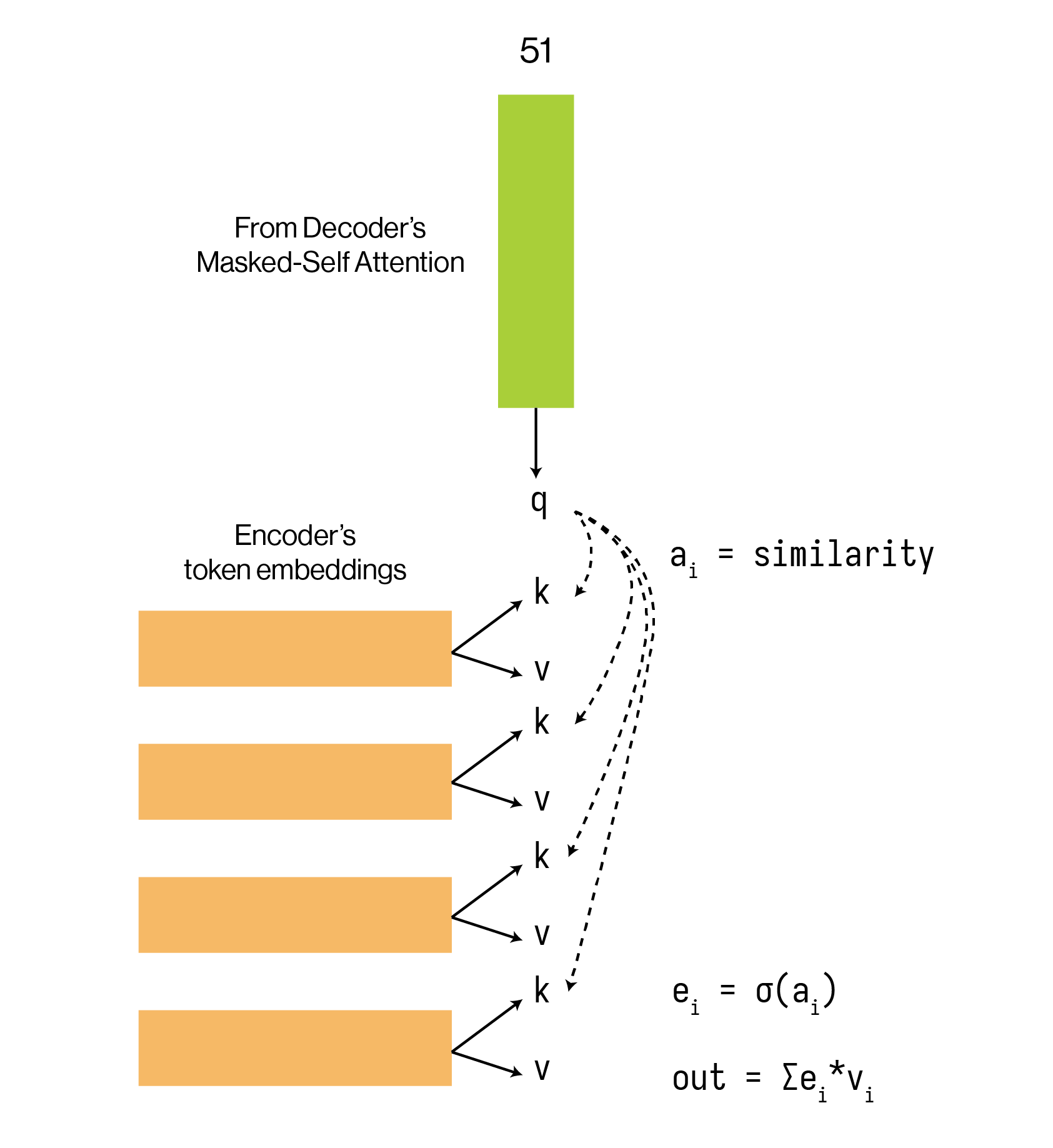
Task: Implement the full Transformer Decoder. Subtasks:
-
Modify
scaled_dot_product_attentioninseq2seq/transformer/attention.py. If you haven’t added this yet, handle the optional mask argument. If thismaskis provided, you must “fill” the attention scores (thematmul(q, k) / ...result) with a very large negative number (like-float('inf')) at all positions where the mask is1. This must be done before applying the softmax. -
Implement all parts of the
Decoderinseq2seq/transformer/decoder.py.-
Implement
DecoderLayer. This will involve creating instances of yourMultiHeadAttention(one for masked self-attention, one for cross-attention) and yourFeedForwardNN. Don’t forget the three residual connections andLayerNorms! You’ll notice you are given both atgt_maskand asrc_maskhere.tgt_maskhas both the causal mask and the pad mask applied for the English input into the Decoder.src_maskhas the pad mask applied to it.You’ll need to think about where to input the
src_maskvs thetgt_mask(hint: the only function that actually deploys any masks is thescaled_dot_product_attentionfunction)Remember that our LM task will be decoder-only, so we don’t want to do cross-attention in this case. When
enc_xisNone, make sure to skip the cross-attention step in yourDecoderLayer. -
Implement
Decoder. This will be aModuleListof yourDecoderLayers, just like in theEncoder. It will also need to handle the target embeddings and positional encoding. Itsforwardmethod will be more complex, as it takes both the target sequencetgtand theenc_x(encoded French).
-
After this step, run:
python -m unittest tests/test_transformer/test_decoder.py
You should be passing all these tests. Once this is done, you have a full Transformer! We’ve implemented the joining of the Encoder and Decoder for you in seq2seq/transformer/transformer.py (take a look!).
Here is the full Transformer architecture now (including the Decoder) for your reference (from Attention Is All You Need paper):
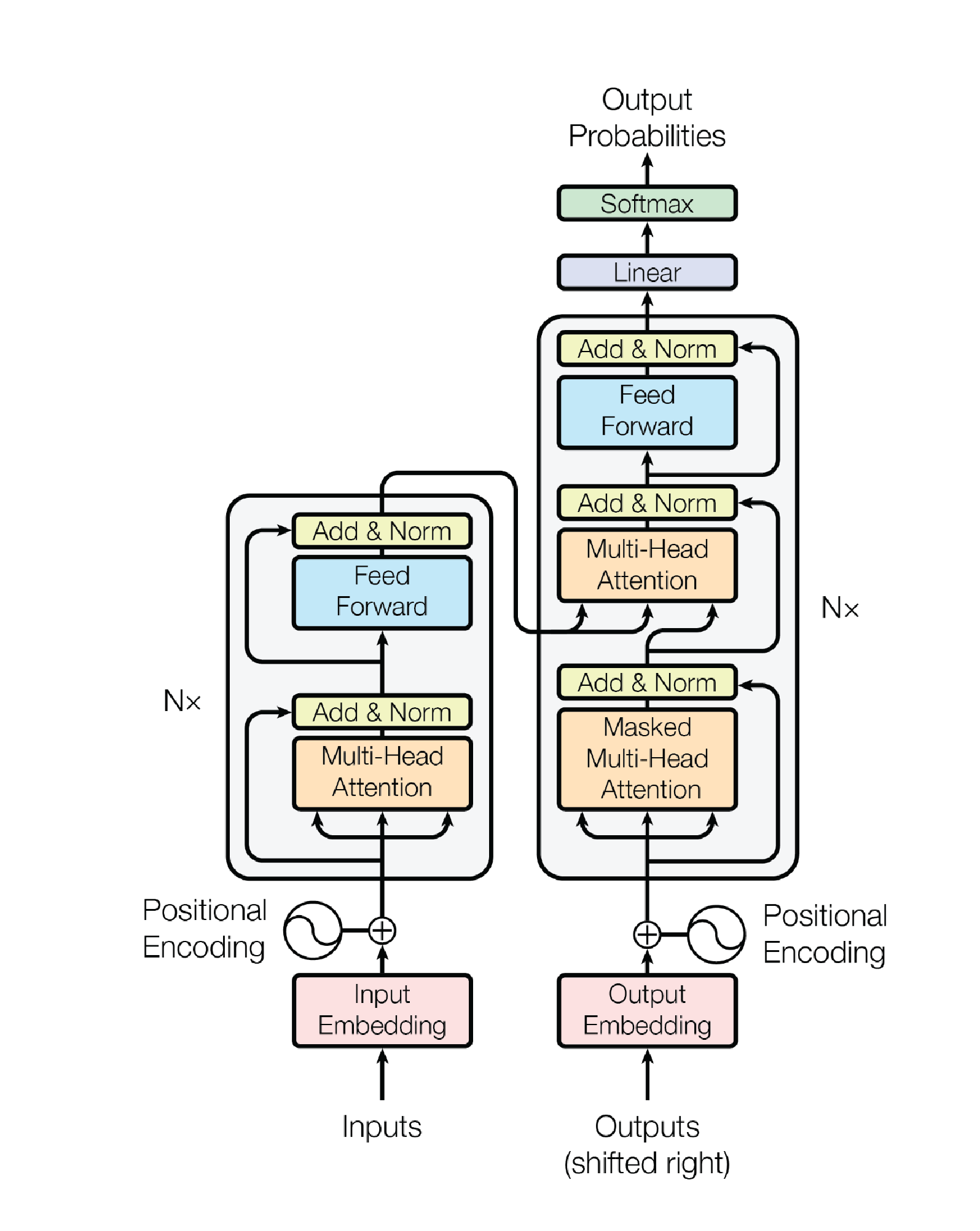
Training
Once we are finished with our architecture, we want to implement our training loops for both the NMT and the LM tasks.
NMT Task
Fill in the TODO sections in scripts/train_nmt.py.
- You’ll need to take a look at
seq2seq/tokenizer/bpe_tokenizer.pyfor details on what index to ignore. - Fill in the
tgt_output. Think carefully about what should be the target input and target output for our model (hint: remember that the Decoder is autoregressive!)
LM Task
We’ve implemented the LM training script for you! Just add the same line that you added in the NMT task in the TODO line in scripts/train_lm.py.
Tracking experiments
We’ve added simple wandb logging to your training scripts. Make sure to fill in your entity names in both scripts to track your experiments!
Start training!
- Set your devices to be different values (based on which GPUs are free on honeydew according to
nvidia-smi). -
Train! You can run:
tmux # open two different panes or two different tmux sessions uv run scripts/train_nmt.py uv run scripts/train_lm.pyand your model should start training!
-
Checkpoints will start saving in your working directory. Once you have checkpoints, you can test your models with:
uv run scripts/decode_nmt.py uv run scripts/decode_lm.pyTake a look at these scripts. In both cases, we basically start with a
BOStoken, produce next token distributions, sample from them, and add to our list of accumulated tokens so far. If we either hit ourmax_lenor anEOStoken, we stop decoding! Feel free to explore different decoding schemes, including greedy, top-\(k\), top-\(p\) (nucleus), and beam search.
Submission
Once you feel as though your model outputs are satisfactory when running the decode scripts, feel free to submit:
- On the HW 4 grading assignment, please submit the text outputs from the
decode_nmt.pyanddecode_lm.pyscripts. - And you’re done! You’ve successfully built and trained
Transformer-based models :)